數據資產盤點,是一個將數據資源進行標準化、產品化、服務化的過程。沒有經過這個過程的數據,僅僅只能是數據資源,就像原油;經過資產盤點,有口徑、有溯源、有案例場景,有服務接口,用戶才能“看得到、用得上、能放心”。
然而,企業在實際的工作中,面對大量的存量數據資源和有限的
數據標準,這是一個N:1的過程。這個過程,如果沒有在這些系統建設之初就進行建模管控,形成標準資源的1:N機制,那么反推回來,要讓N個數據資源項被找到、對齊數據標準,會是一項困難的工作。在這個時候,就必須使用智能化的工具,部分替代人工的識別和評估。
今天的周周談,我們就從實際工作經驗方面總結一下,如何在一個大規模存量系統的環境中,實現這個對標過程。其核心就是:一套業務領域詞庫和向量庫、一套匹配算法、一套對標過程的人工+AI的工作機制。
01數據資產盤點
數據標準是信息架構的重要組件之一,站在全局角度,設置統一的數據標準對企業的業務發展、風險防控、內部管理與風險合規具有重要意義。在開展存量
數據治理中,由于企業數據來源不一,既有在業務發展中積累的數據,也有通過外部合作獲取的第三方數據,且分布在不同的業務系統中。
這些數據紛繁復雜、數量龐大且存在冗余,由于歷史原因,不同系統的庫表字段由不同的業務部門組織開發,采集到的元數據面臨著“同義不同名”等問題。將大量的元數據準確映射到數據標準有助于摸清數據資產的“家底”,以便未來進行數據管理與應用。然而由于采集到的元數據數量動輒上百萬項,過于龐大的數量讓資產盤點面臨著艱巨挑戰,無法在短期內由人工完成。
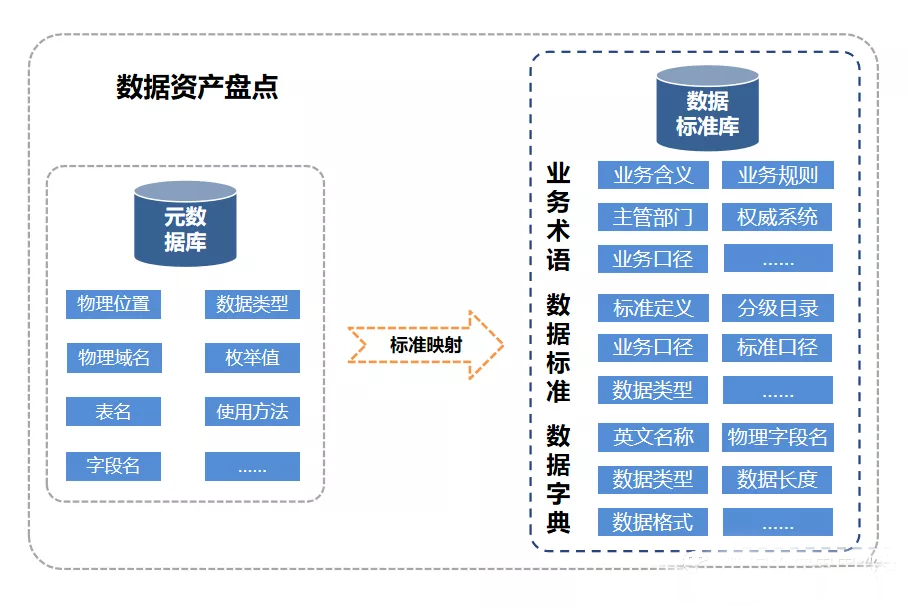
圖片圖1
數據資產管理
借助自然語言處理(NLP)等技術支持,將算法與規則嵌入到映射過程,是實現智能對標、提升盤點效率與保證盤點質量的有效手段。
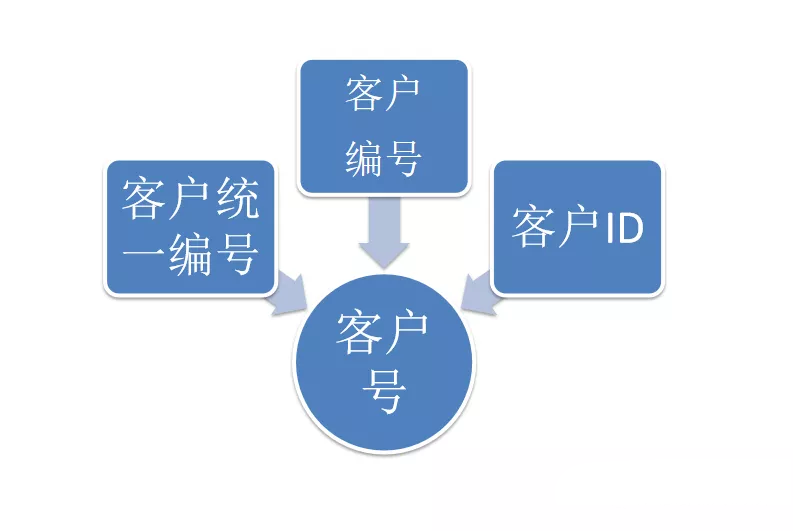
圖2 元數據對標
02智能對標引擎搭建
工欲善其事,必先利其器,智能對標引擎是實施數據資產盤點的重要工具。由于元數據中文名稱與數據標準中文名稱都為長字段或長短語,智能對標引擎首先要解決長短語的模糊匹配問題,其次,在名稱一致或模糊匹配成功后,對元數據的數據類型、數據長度、枚舉值或數據約束等信息與數據標準進行一致性與關聯性校驗,校驗通過后即完成由元數據到數據標準的映射即對標過程。
我們把問題分解完成后,開始著手智能對標引擎開發,詳細搭建過程如下:
1.語料庫與詞向量
首先根據元數據業務系統所屬的特定領域收集相應的語料庫(語料庫指經科學取樣和加工的大規模電子文本庫,其中存放的是在語言實際使用中真實出現過的語言材料),我們利用語料庫進行詞向量(Word2Vec)模型的訓練與搭建。詞向量是語料庫經分詞后產生的詞語或短語在數學意義上的向量化表示,它讓我們能夠從幾何的角度理解語義,并進行可視化,是一種從抽象到具體的過程。詞向量模型的訓練基于如下假設:相同上下文語境的詞具有相同或相似含義。
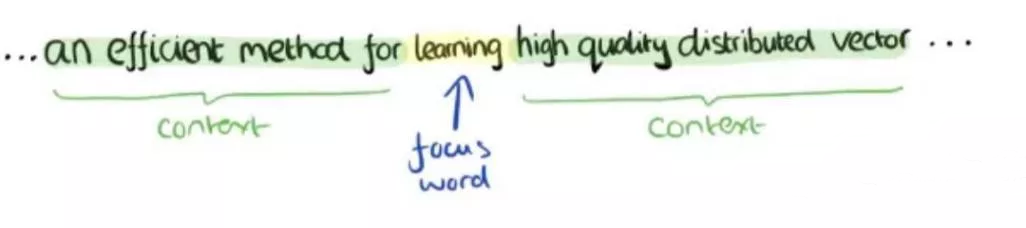
圖3 詞匯的上下文語境
例如“客戶號”與“客戶編號”兩個詞語指的是客戶的同一屬性,具有相同語義且經常出現在相同的上下文語境中,通過計算這兩個詞匯的詞向量距離或夾角,能夠揭示二者相近或相等的關系。在更復雜潛在關系的表達上,詞向量同樣可以做到。例如,King(國王)屬于Man(男性),Queen(王后)屬于Woman(女性),詞向量可以建立如下圖所示的空間向量關系。
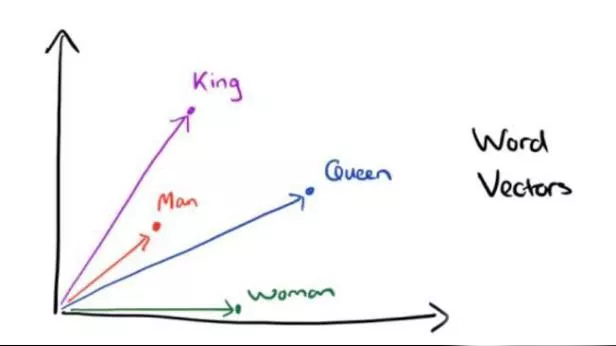
圖4 詞向量空間
2.相似度計算
詞向量模型搭建完成后,我們解決了詞語或短語之間的相似度計算,然而距離我們對標的長短語之間的相似度計算尚有差距。詞語或短語的長度一般在5或以下,可以直接利用詞向量模型計算相似度,而長短語的長度一般在6至15的區間范圍內,只能間接利用詞向量進行相似度計算。
例如“理財產品交易申請日期”這樣的長短語無法直接用詞向量表示。一種常見的想法是把長短語分詞為“理財產品”、“交易”、“申請日期”,然后利用這三個詞匯的詞向量進行加權,求得長短語的加權向量,這樣的方法在計算長短語相似度方面的效果并不理想,達不到對標要求的精度,往往還需要人工進行大量復核。
3.詞移距離與編輯距離
我們通過多種算法組合進行大量嘗試對比后,最終發現基于詞向量模型的詞移距離(Word Mover's Distance,WMD)與編輯距離算法(Edit Distance)的組合取得了相當好的效果,在特定相似度閾值p以上可以實現元數據與數據標準的準確映射,而且無需人工干預與復核。
詞移距離(WMD)利用詞向量提取到的詞語語義特征來計算兩個長短語之間的相似度,即以組成長短語集合的詞語到另一個長短語集合詞語的距離,來表示長短語之間的相似度。接下來看一下詞移距離(WMD)具體的模型。
WMD是通過將一個文檔(長短語)中包含的詞語“移動”(Travel)到另一個文檔(長短語)中的詞語,這個“移動”過程產生的距離總和的最小值作為詞移距離。WMD距離越大相似度越小,WMD距離越小相似度越大。舉個例子,兩個短文本“Obama speaks to the media in Illinois”(“奧巴馬在伊利諾斯州向媒體發表講話”)、“The President greets the press in Chicago”(“總統在芝加哥迎接新聞記者”),那么從第一個句子轉移到第二個句子的示意圖如下(已去除停用詞):
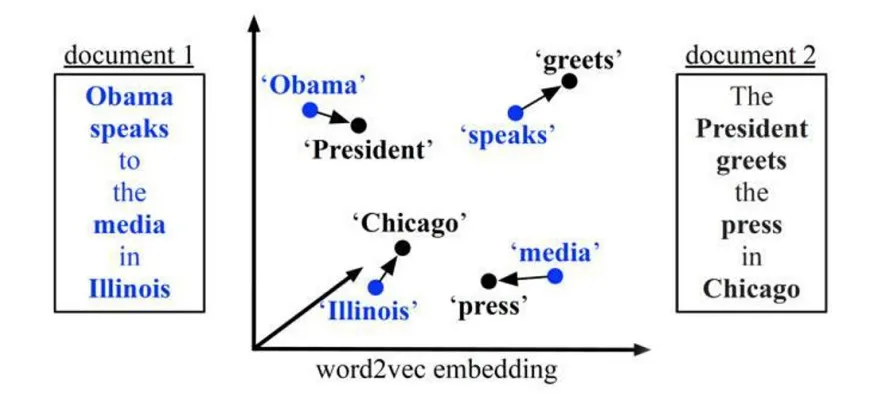
圖5 轉移示意圖
針對示意圖中的詞移距離則表示為:
Distance("Obama"->"President")
+ Distance("speaks"->"greets") + ...
那么詞到詞之間的距離,即如 Distance("Obama"->"President")該怎么計算呢?很明顯我們第一步的詞向量模型已經為此做好了鋪墊。
當然我們在實際使用中是讓第一個句子中的詞以不同的權重轉移到另一個句子的所有詞上,如下圖所示,讀者若有興趣可查閱相關資料,在此不做過多展開。

圖6 加權轉移示意圖
通過詞移距離可以計算長短語之間的相似度,在長短語詞序的平衡上我們又引入了編輯距離來修正。在元數據名稱與數據標準名稱的匹配前我們一般會配置相應規則將名稱中包含的特殊符號與混雜的枚舉值進行剔除,進行字母的大小寫進行一致轉換等操作。
以上過程解決了對標所需的長短語間的模糊匹配問題,名稱匹配完成后,對元數據的數據類型、數據長度、枚舉值或數據約束、所屬業務域等剩余信息與數據標準進行關聯校驗,此校驗一般根據具體需求建立在規則配置之上,校驗通過后即完成由元數據到數據標準的智能對標過程。
表1 智能對標結果示意圖
03智能對標擴展應用
智能對標引擎搭建完成后,將采集到的元數據與數據標準建立映射關系,納入統一管理與應用。對智能對標工具進行持續優化與迭代,定期對業務系統進行全量智能數據對標,加強新增落標項目的重復項檢查,避免重復落標,對實現數據接口管控、推動數據治理進程具有重要意義。
智能對標模型進行改造后可進行大量的擴展應用,如實現業務術語、數據標準、物理字典的相似檢測、詞義消歧、去除重復項等質量提升工作。也可應用于數據標準庫、業務術語知識庫等知識圖譜的智能搜索,實現知識含義之間的關聯與知識推導。例如,通過調用維基百科API等大型知識庫,進行業務術語語義關聯,實現術語的標準化與業務定義的豐富,最終完善業務邏輯關聯助力數據消費,是我們進行的新的嘗試。
(部分內容來源網絡,如有侵權請聯系刪除)

















